Classification K-Means
K-Means est un algorithme de classification non supervisé car le nombre de classes est inconnu, la recherche de classes sera faite à l'aveugle.
Ce type de classification est facile à implémenter et à comprendre, le but ultime de cet algorithme est de regrouper les points selon un critère bien déterminé, en effet l'entrée est un ensemble k groupes (clusters).
Par la suite on vise à calculer la distance entre chaque individu (point) et les k centre, qui sont déjà choisis au début. la plus petite distance est retenue pour inclure cet individu dans le groupe ayant le centre le plus proche.
Une fois tous les individus groupés, on aura k sous-nuages disjoints de la marge total pour chaque groupe, l'algorithme calcule des nouveaux centres de gravité
l'algorithme s’arrête lorsque les groupes construits deviennent stables
Attention :
Le défaut de la méthode c'est qu'on est obligé de fixer le K, aussi le résultat est fortement couplé avec les centres initiaux
J'aime bien expliquer le fonctionnement de cet algorithme par le schéma suivant :

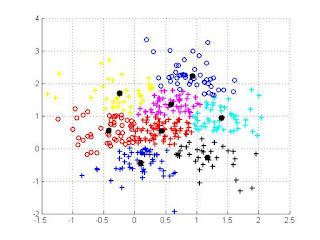
le résultat de l'algorithme est d'avoir un groupement de points regroupés au tour d'un centre de gravité
Ce type de classification est facile à implémenter et à comprendre, le but ultime de cet algorithme est de regrouper les points selon un critère bien déterminé, en effet l'entrée est un ensemble k groupes (clusters).
Par la suite on vise à calculer la distance entre chaque individu (point) et les k centre, qui sont déjà choisis au début. la plus petite distance est retenue pour inclure cet individu dans le groupe ayant le centre le plus proche.
Une fois tous les individus groupés, on aura k sous-nuages disjoints de la marge total pour chaque groupe, l'algorithme calcule des nouveaux centres de gravité
l'algorithme s’arrête lorsque les groupes construits deviennent stables
Attention :
Le défaut de la méthode c'est qu'on est obligé de fixer le K, aussi le résultat est fortement couplé avec les centres initiaux
J'aime bien expliquer le fonctionnement de cet algorithme par le schéma suivant :

le résultat de l'algorithme est d'avoir un groupement de points regroupés au tour d'un centre de gravité

Vous pouvez télécharger mon nouveau plugin sur NuGet en version 1.0.0
PM>Install-Package K-Means -Version 1.0.0



Commentaires
Enregistrer un commentaire